数字货币网报道:
作者:Vitalik Buterin,@vitalik.eth;编译:松雪,
激励协议中更好的去中心化的一种策略是惩罚相关性。 也就是说,如果一个参与者行为不当(包括意外),那么与他们同时行为不当的其他参与者(以总 ETH 衡量)越多,他们受到的惩罚就会越大。 该理论认为,如果你是一个大型参与者,那么你所犯的任何错误都更有可能在你控制的所有“身份”中复制,即使你将你的代币分散到许多名义上独立的账户中。
这项技术已经在以太坊削减(以及可以说是不活动泄漏)机制中得到应用。 然而,仅在极特殊的攻击情况下出现的边缘情况激励措施在实践中可能永远不会出现,可能不足以激励去中心化。
这篇文章建议将类似的反相关激励扩展到更“平凡”的失败案例中,例如错过证明,几乎所有验证者至少偶尔都会这样做。 该理论认为,较大的质押者,包括富有的个人和质押池,将在同一互联网连接甚至同一台物理计算机上运行许多验证器,这将导致不成比例的相关失败。 这样的质押者总是可以为每个节点进行独立的物理设置,但如果他们最终这样做,那就意味着我们已经完全消除了质押的规模经济。
健全性检查:同一“集群”中不同验证器的错误实际上更有可能相互关联吗?
我们可以通过组合两个数据集来检查这一点:(i) 最近一些时期的证明数据,显示在每个时隙期间哪些验证器应该经过证明,以及哪些验证器实际进行了证明,以及 (ii) 将验证器 ID 映射到公开的数据包含许多验证器的集群(例如“Lido”、“Coinbase”、“Vitalik Buterin”)。 您可以在此处、此处和此处找到前者的转储,在此处找到后者的转储。
然后,我们运行一个脚本来计算共同失败的总数:同一集群中的两个验证器的实例被分配在同一时间槽内进行证明,并在该时间槽中失败。
我们还计算预期的共同故障:如果故障完全是随机机会的结果,则“应该发生”的共同故障的数量。
例如,假设有 10 个验证器,其中一个集群大小为 4,其他集群独立,并且 3 个验证器失败:两个在该集群内,一个在集群外。

这里有一个共同失败:第一个集群中的第二个和第四个验证器。 如果该集群中的所有四个验证器都失败了,则会出现六个共同失败,每六个可能的对有一个。
但“应该”有多少共同失败呢? 这是一个棘手的哲学问题。 回答的几种方式:
对于每次失败,假设共同失败的数量等于该时隙中其他验证器的失败率乘以该集群中验证器的数量,并将其减半以补偿重复计算。 对于上面的例子,给出了2/3。
计算全局故障率,平方,然后乘以[n*(n-1)]/2对于每个集群。 这是给定的[(3/10)^2]*6=0.54
将每个验证者的失败随机重新分布到其整个历史记录中。
每种方法都不是完美的。 前两种方法未能考虑具有不同质量设置的不同集群。 同时,最后一种方法未能考虑到具有不同固有困难的不同时隙所产生的相关性:例如,时隙 8103681 具有大量的证明,这些证明未包含在单个时隙中,可能是因为该块已发布异常迟到。
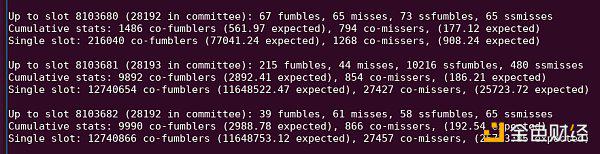
请参阅此 python 输出中的“10216 ssfumbles”。
我最终实现了三种方法:上面的前两种方法,以及一种更复杂的方法,我将“实际共同失败”与“假共同失败”进行比较:每个集群成员被替换为(伪)随机验证器的失败具有相似的故障率。
我还明确区分了失误和错过。 我对这些术语的定义如下:
失误:当验证者在当前时期错过证明,但在上一个时期正确证明时;
错过:当验证者在当前时期错过了证明并且在上一个时期也错过了证明时。
目标是区分两种截然不同的现象:(i) 正常运行期间出现网络故障,以及 (ii) 离线或出现长期故障。
我还同时对两个数据集进行此分析:最大截止日期和单槽截止日期。 仅当根本不包含证明时,第一个数据集才会将验证器视为在一个时期内失败。 如果证明未包含在单个槽中,第二个数据集将验证器视为失败。
以下是我对前两种计算预期共同故障的方法的结果。 这里的 SSfumbles 和 SSmisses 是指使用单时隙数据集的失球和失误。
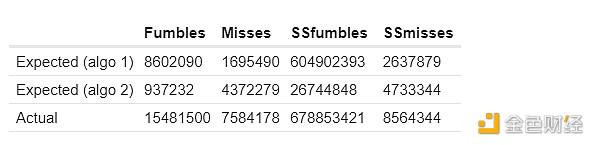
对于第一种方法,实际行有所不同,因为为了提高效率,使用了更受限制的数据集:

“预期”和“假集群”列显示,如果集群不相关,基于上述技术,集群内“应该”有多少共同故障。 “实际”列显示实际有多少共同故障。 一致地,我们看到集群内“过多相关失败”的有力证据:同一集群中的两个验证器比不同集群中的两个验证器同时错过证明的可能性明显更大。
我们如何将其应用到惩罚规则中?
我提出了一个简单的论点:在每个槽中,令 p 为当前错过的槽数除以最后 32 个槽的平均值。
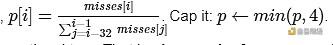
该时隙证明的惩罚应与 p 成正比。
也就是说,与其他最近的槽位相比,未证明某个槽位的惩罚应与该槽位中失败的验证者数量成正比。
这种机制有一个很好的特性,那就是它不容易被攻击:在任何情况下,失败都会减少你的惩罚,并且操纵平均值足以产生影响需要你自己进行大量的失败。
现在,让我们尝试实际运行它。 以下是四种惩罚方案对大集群、中集群、小集群和所有验证器(包括非集群)的总惩罚:
基本:每次失误扣一分(即类似于现状)
basic_ss:相同,但需要包含单槽才算作未命中
超额:用上面计算的 p 来惩罚 p 点
extra_ss:用上面计算的 p 来惩罚 p 点,要求单槽包含不计为未命中

使用“基本”方案,大方案比小方案有约 1.4 倍的优势(在单槽数据集中约 1.2 倍)。 使用“额外”方案,该值下降至约 1.3 倍(在单时隙数据集中约 1.1 倍)。 通过多次其他迭代,使用略有不同的数据集,超额惩罚方案统一缩小了“大人物”相对于“小人物”的优势。
这是怎么回事?
每个插槽的故障数量很少:通常只有几十个。 这比几乎任何“大额股份”都要小得多。 事实上,它比大型质押者在单个槽位中活跃的验证者数量还要少(即其总存量的 1/32)。 如果大型质押者在同一台物理计算机或互联网连接上运行许多节点,那么任何故障都可能会影响其所有验证器。
这意味着:当大型验证者出现证明包含失败时,他们会单枪匹马地改变当前槽的失败率,这反过来又会增加他们的惩罚。 小型验证器不会这样做。
原则上,大股东可以通过将每个验证者置于单独的互联网连接上来绕过这种惩罚方案。 但这牺牲了大型利益相关者能够重用相同物理基础设施的规模经济优势。
进一步分析
寻找其他策略来确认这种影响的大小,其中同一集群中的验证器很可能同时出现证明失败。
尝试找到理想的(但仍然简单,以免过度拟合和不可利用)奖励/惩罚方案,以最小化大型验证者相对于小型验证者的平均优势。
尝试证明此类激励方案的安全特性,理想情况下确定一个“设计空间区域”,其中奇怪攻击的风险(例如,在特定时间战略性地离线以操纵平均值)成本太高,不值得。
按地理位置聚类。 这可以决定该机制是否也能激励地理上的去中心化。
通过(执行和信标)客户端软件进行集群。 这可以决定该机制是否也能激励使用少数客户。
编辑:web3528btc 来源:加密钱包代币
