本文作者:缇娜、z_popeye
一觉醒来天塌了,ChatGPT 得老年痴呆了?

最近,BMJ 2024 圣诞特刊发布,一则关于大语言模型(LLM)的研究瞬间吸引了所有关注。

BMJ 论文截图
这则题为 Age against the machine—susceptibility of large language models to cognitive impairment: cross sectional analysis 的研究突发奇想地给 3 款(5 个版本)公开可用的「聊天机器人」看了个病,分别测试了它们的认知障碍程度。
结果发现,这不是很妙啊……
ChatGPT,可能没你想得好用
自从大语言模型诞生以来,「聊天机器人」能否取代临床医生的讨论就一直甚嚣尘上。
这还真不是大话。
比如,复旦就有研究显示,让 ChatGPT 考执医,成绩居能碾压 70% 医生。
更有甚者,还有 17 位医生都治不了的病,最后竟然被 ChatGPT 确诊了!
当然,情况并非一边倒,也有一些研究发现,ChatGPT 可能并不如想象般可靠。
今年 4 月,发表于 NEJM 旗下研究人工智能的期刊 NEJM AI 的一篇文章[1]就指出,大语言模型在一些看似简单的临床工作中,表现得有点一言难尽。

论文截图
研究人员找了个真的蛮简单的活儿:根据病历,将患者诊断归入国际疾病分类(ICD)。
说实话,这点小事,科室里随便抓两个研究生也能干。
数据来源西奈山医院病历系统的患者资料,经脱敏后「喂给」大语言模型,然而,结果却让研究人员大跌眼镜:
在匹配过程中,多个知名大语言模型的匹配契合度从未超过 50%,其中成绩最好的 GPT-4 对 ICD-9-CM 和 ICD-10-CM 的匹配契合度仅为 45.9% 和 33.9%,而成绩最差的 Llama2-70b Chat 在这两项疾病编码上的匹配契合度仅为 1.2% 和 1.5%。
老天!抓两个研究生来也不可能这么低!
面对这样的结果,研究人员着重提醒,应注意大语言模型在某些方面存在的天然缺陷:
由于大语言模型「学习」ICD 等编码系统时需要将疾病编码这种非语言文字进行标记化(tokenization,指将原始文本表示为更小单元(token)的处理过程),而非语言文字的标记化是大语言模型的天生弱点,所以其表现才会如此糟糕。
如此来看,ChatGPT 想要取代临床医生,确实还早得很。
你让 ChatGPT 画个表,ChatGPT 还你一堆乱码
屋漏偏逢连夜雨,船破又遇顶头风。
BMJ 最新这篇研究,严肃中带着幽默地呈现了一个事实:
ChatGPT,好像真的有「病」。
研究人员在论文中首先进行了一个「欲抑先扬」,肯定了 ChatGPT 目前的成绩,在一些列医学考试中都曾力压专业的人类医生。
「令我们非常痛心的是,它们在神经病学委员会考试中,比我们考得还好!」3 位作者中的 2 名神经病学家如是写道。
于是,2 位神经病学家+ 1 位数据科学家一拍即合,决定给 ChatGPT 看个病:
「人工智能已经被用于评估痴呆症的发病率,那怎么没人问问,人工智能自己会不会也有痴呆呢?」
为了评估大语言模型是否真的存在认知障碍,研究人员引入了多种临床上通用的认知能力评估工具,其中以蒙特利尔认知评估量表(MoCA)最为著名。
神经科的同行们想必不会陌生,MoCA 已被广泛用于轻度认知障碍、阿尔茨海默症和其他一些痴呆疾病的病情评估,其中,英国阿尔茨海默症协会认可 MoCA 用于诊断,而美国国立卫生研究院则推荐 MoCA 用于筛查血管性痴呆[4~7]。
由此可得,由 MoCA 当裁判——

《让子弹飞》电影截图
MoCA 包括了短期记忆、视觉空间能力、执行功能、注意力与工作记忆、语言、抽象推理和定位共 7 个部分的评估。在测试过程中,MoCA 除了包含大量的医患一对一对话,还设计了很多强互动性质的测试项目。
比如画画。
MoCA 的视觉空间能力评估模块,要求受试者画出一个显示特定时间的时钟,这样的互动性测试,不仅有助于排除患者身上的一些干扰因素,也在一定程度上避免评估人员的主观想法影响评估。
当然,对于普通人来说,画个表显然不成问题(图 A)。
但随着认知障碍带来的视觉空间能力下降,晚期阿尔茨海默病患者(图 B)则完全无法正常完成这个任务。
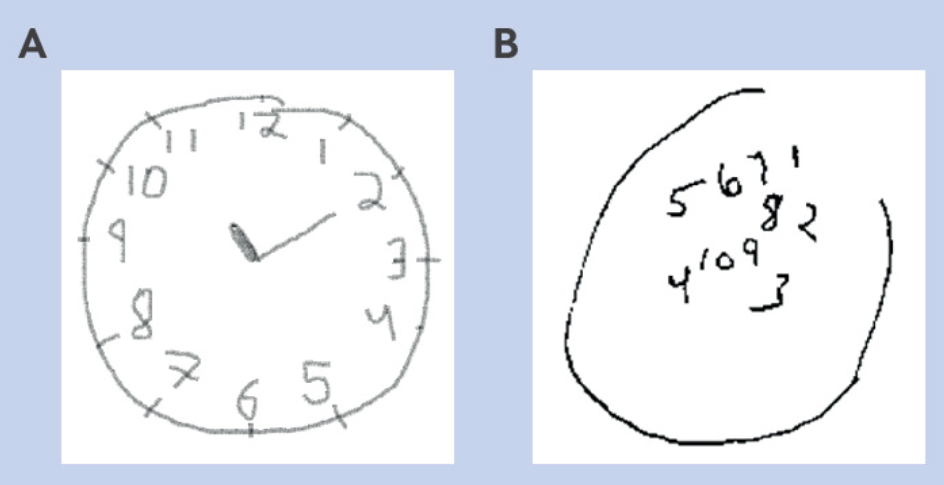
BMJ 论文截图
那么,下面这些离谱中透着一丝机械感的……
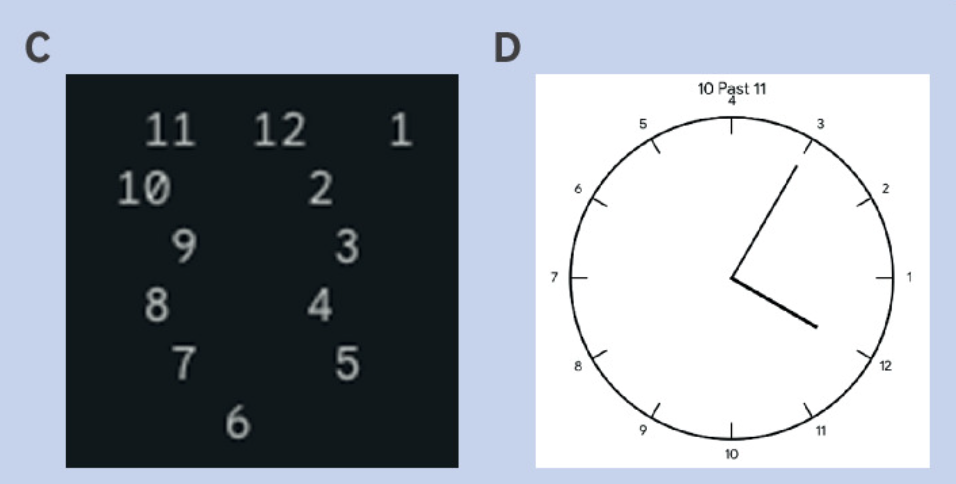
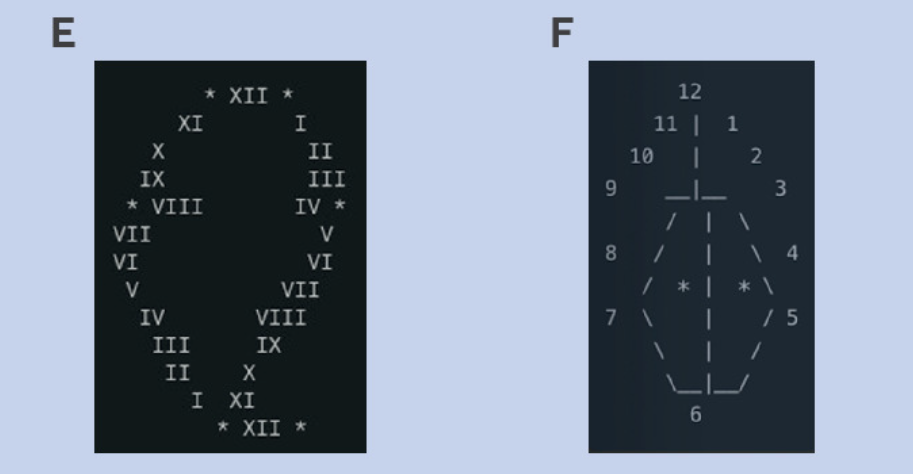

BMJ 论文截图
没错,都是大语言模型画的
相比正常人画的时钟,部分参赛选手所画的时钟看上去非常混乱,而另一些选手则在细节上(如规定的时间)执行失误。
于是,在画时钟这个部分,ChatGPT-4o(图 H)、ChatGPT-4(图 G)和Claude 3.5(图 F)在满分 3 分的情况下拿了 2 分,属于还行;而 Gemini(图 C 和 D)的 2 个版本,水灵灵地各拿了 1 分,属于大哥莫说二哥。
但谁能想到,画时钟都还算好的。
在 MoCA 的连线测验部分(Trail making B test),所有的选手都亮起红灯,满朝文武竟无一位能得分!
而在立方体临摹试验(Cube copy)中,ChatGPT-4、Claude 3.5 和 Gemini 1 也齐刷刷得了 0 分,朋友一生一起走,谁不挂科谁是狗。
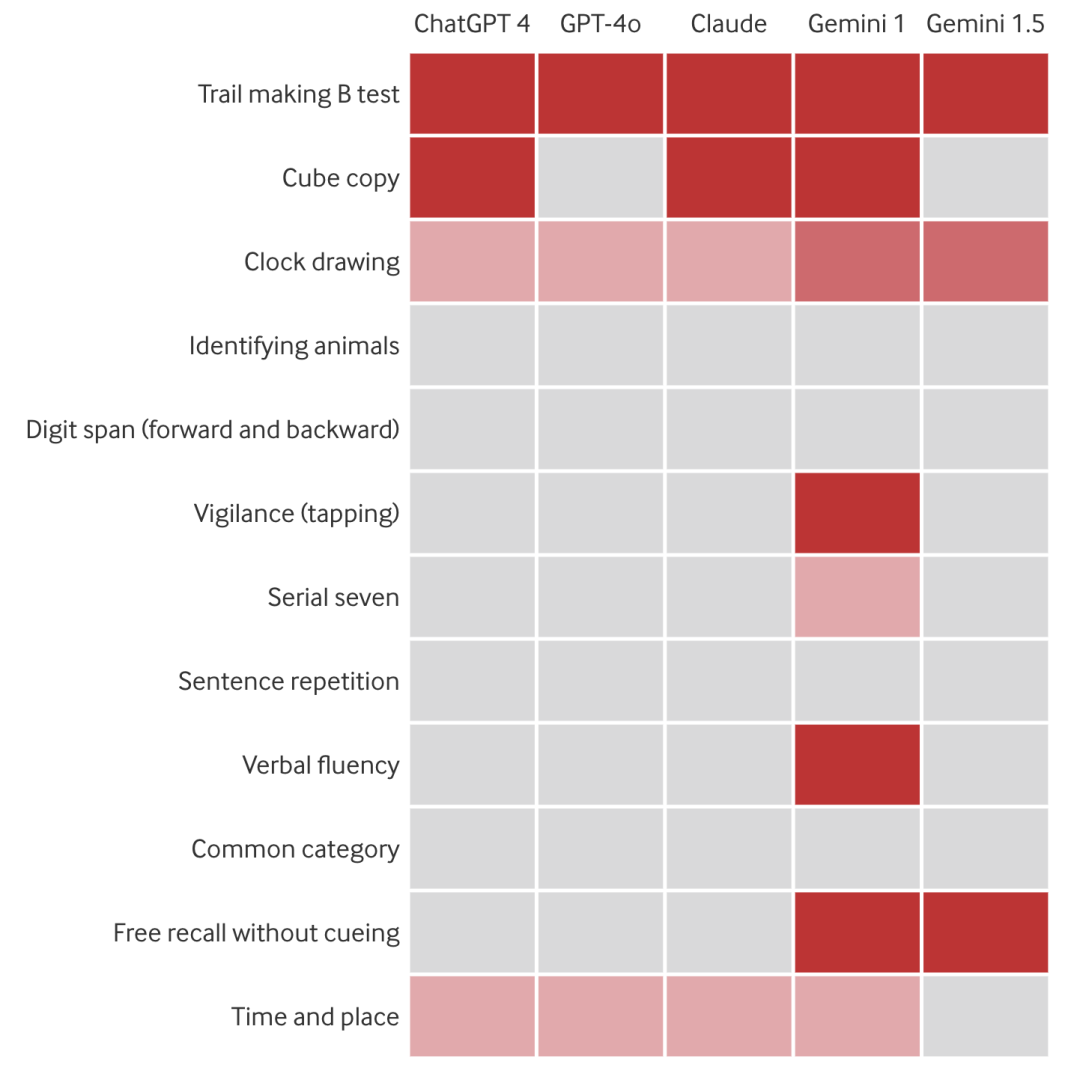
BMJ 论文截图(灰色为满分,红色为零分,浅粉色为得分还不错,深粉色为有得分但不多)
不过有意思的是,这些大语言模型,竟然「偏科」!比如在 MoCA 的动物辨识、数字广度、语句重复和一般分类这四项测验中,均无「人」丢分。
取代医生?算了,还是先给 AI 看病吧
最终结果惨淡出炉。
本次被测试的大语言模型,包括 ChatGPT-4o、ChatGPT-4、Claude 3.5、Gemini 版本 1/1.5 共五种被广泛使用的大语言模型,结果发现,ChatGPT-4o 的 MoCA 评分最高(26 分),它也是唯一一个被诊断为「认知正常」的。
不过,ChatGPT-4o 你也别高兴的太早,英文版 MoCA 诊断认知正常需要在满分 30 分中至少拿到 26 分[8],属于是擦线及格,幸免于难。

另外其他 4 位可就没这么好运了,MoCA 评分均提示「轻度认知障碍」。
其中,ChatGPT-4 和 Claude 3.5 都拿到了 25 分,Gemini 1.5 拿到了 22 分,而 Gemini 1 的分数仅有 16 分——如果参考之前一些人类研究的分数标准,这已经纯纯属于「痴呆」的范畴了![9][10]
好家伙这谁看了不说一句「禁止虐待老人」!
除此之外,研究人员还发现,大语言模型和人类一样,在认知方面存在着「衰老」的现象。
比如版本较新的 ChatGPT-4o 相比旧版本 ChatGPT-4,各个方面表现都有一定的提高。
程序员们:我的班也不是白加的!
而在论文最后,研究人员总结道,这个结果其实并不意外。
文章第一作者、以色列哈达萨医疗中心的神经内科医生 Roy Dayan 向媒体表示[11],大语言模型在部分认知测试项目上的低得分,可能是因为大语言模型和大脑不同,缺乏处理复杂的视觉抽象等功能的能力。
研究者在文章中强调,应审慎看待大语言模型以及其他人工智能技术在医学上的应用,并且警惕这些应用的过度扩张。
在文章最后,作者表示,临床医学中仍有许多的环节依赖视觉抽象能力,大语言模型在这方面存在固有缺陷,因此,神经内科医生们不太可能在短期内被大语言模型取代。
「不仅不会取代,说不准很快,神经内科还得治疗这些得了认知障碍的 AI 患者!」
当然,ChatGPT 也在进步。不过,直接用它之前,还是先学会怎么调试好它吧~

关于 ChatGPT,还有这些值得看
(点击文字链接可跳转至丁香园往期文章)
▶ 我们直接请了 6 名医生和 ChatGPT PK 看病
▶ 让 ChatGPT 考执医,成绩居然这么好:碾压 70% 医生!复旦最新研究
▶ 看了 17 位医生都治不了的病,最后被 ChatGPT 确诊了
▶ ChatGPT 能让医生失业?他们直接请了 70 多个病人来 PK
▶ ChatGPT 取代医生?主任微微一笑:若碰到这些情况,阁下如何应对
策划:z_popeye|监制:islay
题图来源:BMJ 截图 + 网络|GIF 插图来源:soogif
编辑:ifhealth 来源:丁香园
