来源:远川科技评论
轰动全球的大型连续剧“奥特曼去哪儿”划上了句号,但OpenAI的烦心事并没有结束。
Sam Altman能在短时间内官复原职,离不开微软忙前忙后。今年以来,微软一直在帮助好兄弟做大做强。不仅追加投资了100亿美金,还大规模调用了微软研究院的人力,要求放下手头的基础科研项目,全力将GPT-4等基础大模型落地成产品,用OpenAI武装到牙齿。
但很多人不知道的是,今年9月,微软研究院负责人Peter Lee曾接到过一个秘密项目——打造OpenAI的替代品。
第一个“去OpenAI化”的,正是微软的首个大模型应用Bing Chat。
据The Information爆料,微软正尝试将原本集成在Bing当中的OpenAI大模型,逐步替换成自研版本。11月的Ignite开发者大会上,微软宣布Bing Chat更名为Copilot,如今市场定位与ChatGPT颇为相似——很难不让人多想。
全新的Copilot
不过,微软的初衷并不是OpenAI的技术能力有瑕疵,也不是预见到了OpenAI管理层的分歧,真实原因有点让人哭笑不得:
因为OpenAI的技术能力太强了。
开着兰博基尼送外卖
促使微软自研大模型的契机,是OpenAI的一次失败。
ChatGPT轰动全球之际,OpenAI的计算机科学家们正在忙于一个代号为Arrakis的项目,希望对标GPT-4打造一个稀疏模型(sparse model)。
这是一种特殊的超大模型:处理任务时,模型只有特定部分会被激活。例如当用户需要生成一段摘要时,模型会自动激活最适合该工作的部分,不必每次都调动整个大模型。
相较于传统的大模型,稀疏模型拥有更快的响应速度和更高的准确性。更重要的是它可以大大降低推理的成本。
翻译成人话就是,杀鸡再也不用牛刀了——而这正是微软所看重的。

谷歌对稀疏模型优势的总结
舆论聊到大模型成本时,总爱谈论7、8位数的训练成本,以及天文数字的GPU开支。但对大多数科技公司而言,模型训练和数据中心建设只是一次性的资本开支,一咬牙并非接受不了。相比之下,日常运行所需的昂贵推理成本,才是阻止科技公司进一步深入的第一道门槛。
因为在通常情况下,大模型并不像互联网那般具备明显的规模效应。
用户的每一个查询都需要进行新的推理计算。这意味着使用产品的用户越多、越重度,科技公司的算力成本也会指数级上升。
此前,微软基于GPT-4改造了大模型应用GitHub Copilot,用于辅助程序员写代码,收费10美元/月。
据《华尔街日报》的爆料,由于昂贵的推理成本,GitHub Copilot人均每月亏20美金,重度用户甚至可以给微软带来每个月80美金的损失。

GitHub Copilot
大模型应用的入不敷出,才是推动微软自研大模型的首要原因。
OpenAI的大模型在技术上依旧遥遥领先,长期位于各大榜单的首位,但代价是昂贵的使用成本。
有AI研究员做过一笔测算,理论上GPT-3.5的API价格,几乎是开源模型Llama 2-70B推理成本的3-4倍,更别提全面升级后的GPT-4了。
然而除了代码生成、解决复杂数学难题等少数场景,大部分工作其实完全可以交由参数较小的版本和开源模型。
初创公司Summarize.tech就是个活生生的案例。它的业务是提供总结音视频内容的工具,拥有约20万月活用户,早期曾使用GPT-3.5来支持其服务。
后来,该企业试着将底层大模型更换成开源的Mistral-7B-Instruct,发现用户并没有感知到差异,但每月的推理成本却从2000美元降低至不到1000美元。
也就是说,OpenAI为客户无差别提供动力强劲的兰博基尼,但大部分客户的业务其实是送外卖——这构成了OpenAI的“遥遥领先难题”。
所以不光是微软,连Salesforce、Wix等OpenAI的早期大客户,也已经替换成更便宜的技术方案。
降低推理成本,让“开奥迪比雅迪更便宜”,成为了OpenAI必须要解决的课题,这才有了前文提到的稀疏模型项目Arrakis。
事实上,不光是OpenAI,谷歌也在从事相关研究,并且已经取得了进展。8月的Hot Chips大会上,谷歌首席科学家、原谷歌大脑负责人杰夫·迪恩更在演讲中提到,稀疏化会是未来十年最重要的趋势之一。

杰夫·迪恩还发表过稀疏模型的论文
正是遥遥领先带来的高成本让微软琢磨起了“自力更生”的可能性,OpenAI其实也注意到了这个问题:
11月6日的开发者大会上,OpenAI推出了GPT-4 Turbo,一口气降价1/3,已低于Claude 2——即最大竞争对手Anthropic开发的闭源大模型。
OpenAI的“兰博基尼”虽然还不够便宜,至少比其他小轿车实惠了不少。
可惜11天之后,一场足以载入科技史的闹剧,正使得这一努力大打折扣。据外媒爆料,在奥特曼与OpenAI董事会谈判回归的那个周末,已有超过100个客户联系了友商Anthropic。
商业化的悖论
即便没有这场内乱,OpenAI的客户流失危机可能依然存在。
这要从OpenAI的模型与产品设计思路讲起:
不久前,OpenAI往开发者社群中投入了GPTs这颗重磅炸弹。用户可以利用自然语言来定制不同功能的聊天机器人。截止至奥特曼复职当天,用户已上传了19000个功能迥异的GPTs聊天机器人,平均日产1000+,活跃程度堪比一个大型社区。

功能迥异的GPTs
众所周知,GPT模型并不开源,而且还有“遥遥领先难题”。但对个人开发者和小型企业来说,OpenAI具备两个开源模型所无法匹敌的优势:
其一是开箱即用的低开发门槛。在海外论坛上,一些利用OpenAI基础模型搞开发的小型团队,会将自家产品形容为“wrappers(包装纸)”。因为GPT模型强悍的通用能力,他们有时只需要替模型开发一个UI,再找到适用场景,就能拿到订单。
开发者如果需要进一步微调模型,OpenAI同样提供了一项名为的LoRA(低秩自适应)的轻量级模型微调技术。
简单来说,LoRA的大致原理是先将大模型“拆散”,再面向指定任务做适应性训练,进而提升大模型在该任务下的能力。LoRA主要着眼于调整模型内部结构,并不需要太多行业数据进行微调。
但在定制开源模型时,开发者有时会使用全量微调。虽然在特定任务上表现更好,但全量微调需要更新预训练大模型的每一个参数,对数据量要求极高。
相比之下,OpenAI模式显然对普通开发者更加友好。
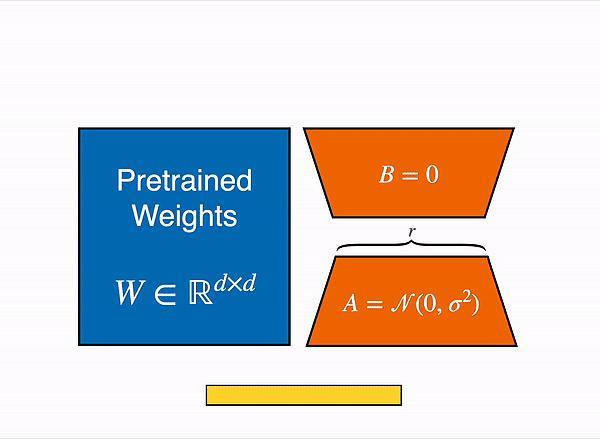
LoRA原理示意图
其次,前文曾提到大模型并不具备规模效应,但这句话其实有一个前提——即计算请求充足的情况下。
测试显示,每批次发送给服务器的计算请求越少,对算力的利用效率会降低,进而会导致单次计算的平均成本直线上升。
OpenAI可以一次性将所有客户的数百万个计算请求一起捆绑发送,但个人开发者和中小企业却很难做到这一点,因为并没有那么多活跃用户。
简单来说就像送快递,同样从上海到北京,OpenAI客户多,可以一次送100件;其他模型就凑不出这么多了。
咨询公司Omdia的分析师曾评价称,OpenAI从规模效应中的获利,远远超过大多数在AWS或Azure上托管小型开源模型的初创企业。
所以,虽然“ChatGPT一更新就消灭一群小公司”的现象客观存在,但还是有不少开发者愿意赌一把。
PDF.ai的创始人Damon Chen就是直接受害者,PDF.ai的主要功能是让模型阅读PDF文件,结果10月底ChatGPT也更新了这项能力。但Damon Chen却非常淡然:“我们的使命不是成为另一家独角兽,几百万美金的年收入已经足够了”。
但对于富可敌国的大公司来说,OpenAI的这些优势全都成了劣势。
比如,OpenAI在轻量级开发上颇有优势,但随着企业不断深入场景,需要进一步定制时,很快会又一次面临“遥遥领先难题”:
由于GPT-4过于复杂且庞大,深度定制需要耗费最低200万美金和数月的开发时间。相比之下,全量微调开源模型的成本多为数十万美元上下,两者明显不是一个量级。
另外,微软、Salesforce等大客户自己的计算请求就够多了,根本不需要和别人一起拼单降成本,这让OpenAI在成本端优势全无。即便是初创企业,随着用户不断增加,使用OpenAI模型的性价比也会降低。
前文提到拥有20万月活的初创公司Summarize.tech,就成功利用开源的Mistral-7B-Instruct降本50%以上。
要知道7B参数的小型开源模型还可以运行在“老古董”级的英伟达V100上——该GPU发布于2017年,甚至没进美国芯片出口管制名单的法眼。
Summarize.tech
从商业角度看,能够支撑公司营收的恰恰是财大气粗的大公司,如何抓住那些“野心不止数年收入百万美金”的客户,已是OpenAI必须面对的命题。
闪点事件
让OpenAI“面对商业化问题”听上去似乎有些奇怪,毕竟直到2023年初,跟赚钱相关的议题还远不在OpenAI的日程表上,更别提搞什么开发者大会了。
今年3月,OpenAI总裁布罗克曼(Greg Brockman)——也就是上周和奥特曼一起被开除的大哥——接受了一次采访。他坦诚地说道,OpenAI并没有真正考虑过构建通用的工具或者垂直领域的大模型应用。虽然尝试过,但这并不符合OpenAI的DNA,他们的心也不在那里。
持续四天半的闹剧之后,Brockman也再度回归
这里的DNA,其实指的是一种纯粹理想主义、保护人类免受超级智能威胁的科学家文化。毕竟OpenAI的立身之本很大程度上建立在2015年马斯克与奥特曼的“共同宣言”——AI更安全的道路将掌控在不受利润动机污染的研究机构手中”。
理想主义大旗的号召下,OpenAI成功招募到了以伊利亚(Ilya Sutskever)为首的顶尖科学家团队——尽管当时奥特曼提供给他们的薪资还不足谷歌一半。
让OpenAI开始转变的一个关键因素,恰恰是ChatGPT的发布。
最初,OpenAI领导并没有将ChatGPT视作一款商业化的产品,而是将其称为一次“低调的研究预览”,目的是收集普通人与人工智能交互的数据,为日后GPT-4的开发提供助力。换句话说,ChatGPT能火成这样,是OpenAI没有想到的。
出乎意料的爆红改变了一切,也促使奥特曼和布罗克曼转向了加速主义。
所谓加速主义,可以简单理解为对AGI的商业化抱有无限热情,准备大干快上跑步进入第四次工业革命。与之对应的则是安全主义,主张用谨慎的态度来发展AI,时刻衡量AI对人类的威胁。
一位匿名OpenAI员工在接受《大西洋月刊》采访时说道,“ChatGPT之后,收入和利润都有了明确的路径。你再也无法为‘理想主义研究实验室’的身份做辩护了。那里有客户正等着服务。”

ChatGPT也催生了“科技界最好的兄弟情谊”
这种转变让OpenAI开始踏入一个陌生的领域——持续将研发成果转换成受欢迎的产品。
对一家曾以理想主义标榜的象牙塔来说,这项工作显然有些过于“接地气”了。比如技术领袖伊利亚就是个计算机科学家而非产品经理,之前在谷歌也多负责理论研究,产品落地的职责在杰夫·迪恩领导的谷歌大脑团队身上。
在ChatGPT发布前,OpenAI更像是几个财富自由的科学家和工程师组成的小作坊,但时过境迁,他们变成了一个正儿八经的商业机构。
过去一年,OpenAI新增了数百位新雇员,用于加速商业化。根据The Information的报道,OpenAI的员工总数很可能已经超过700人。就算不考虑赚钱,也得有方法应对运营成本——毕竟科学家也要还房贷啊。
短暂又剧烈的“奥特曼去哪儿”事件并没有解决这个问题,反而让它变得愈发尖锐:OpenAI到底是个什么组织?
在CNBC的一次采访里,马斯克曾这样形容由他亲手创办、后来又将他扫地出门的公司:“我们成立了一个组织来拯救亚马逊雨林,但后来它却做起了木材生意,砍伐了森林将其出售。”
这种矛盾使得OpenAI困于遥遥领先,也催生了这场惊呆所有人下巴的闹剧。
今年早些时候,连线杂志的记者曾跟访了奥特曼一段时间,期间也曾反复提及这个问题,但奥特曼每次都坚称,“我们的使命没有改变”。但当信奉安全主义的伊利亚滑跪,以及奥特曼回归,显然OpenAI已经做出了它的选择。
编辑:web3528btc 来源:加密钱包代币
